
Client2vec, finding a better way to understand client’s preferences
Computational linguistic has advanced at great strides these last few years. It has permitted, for instance, extracting the semantics of a word just by analyzing its context, without a dictionary, and using relatively simple neural networks. Facebook Research’s Tomas Mikolov pioneered a more efficient process with his word2vec work, now a patented methodology by Google. His work helped machines to understand relations among words that have a close semantic relationship. Incorporating the approach of word2vec to language translation improved the reliability and agility of these services, which have been lagging behind due to the difficulty of understanding the context. Subsequently, many other different methods to embed words and documents have appeared, enriching the toolset. Inspired by the experiences in this field, at BBVA Data & Analytics we are testing Client2vec, a similar approach to understanding client’s behavior.
This same approach, aimed at making the workflow in data science and insights discovery more efficient and productive, led mathematician and BBVA Data & Analytics Data Scientist Leonardo Baldassini to explore ways in which banking can tackle challenging use cases like client segmentation.
Client2vec is an internal library that uses marginalized stacked denoising autoencoders on current account transactions data to create vector embeddings which represent the behaviors of clients. These representations can then be used in, and optimized against, a variety of tasks such as client segmentation, profiling, and targeting.
What if we could read customer needs the same way we understand the meaning of words in a sentence, not relying only on sociodemographic data or the value of a transaction, and optimizing clustering of clients considering their behavior as consumers and not income or zip code?
Baldassini discovered in the course of his research, done in collaboration with BBVA D&A’s senior Data Scientist Jose Antonio Rodríguez Serrano, that grouping traveler’s preferences according to sociodemographic criteria was almost as inaccurate as doing it running a random clusterization. Instead, by applying the Client2vec approach he could regroup travelers by spending patterns. In order to prove his hypothesis, he removed the data from the hotel expenditure category and verified that he could predict whether hotel accommodation was going to be present when a common purchasing pattern identifying the typical traveler’s behavior was present (see image below).
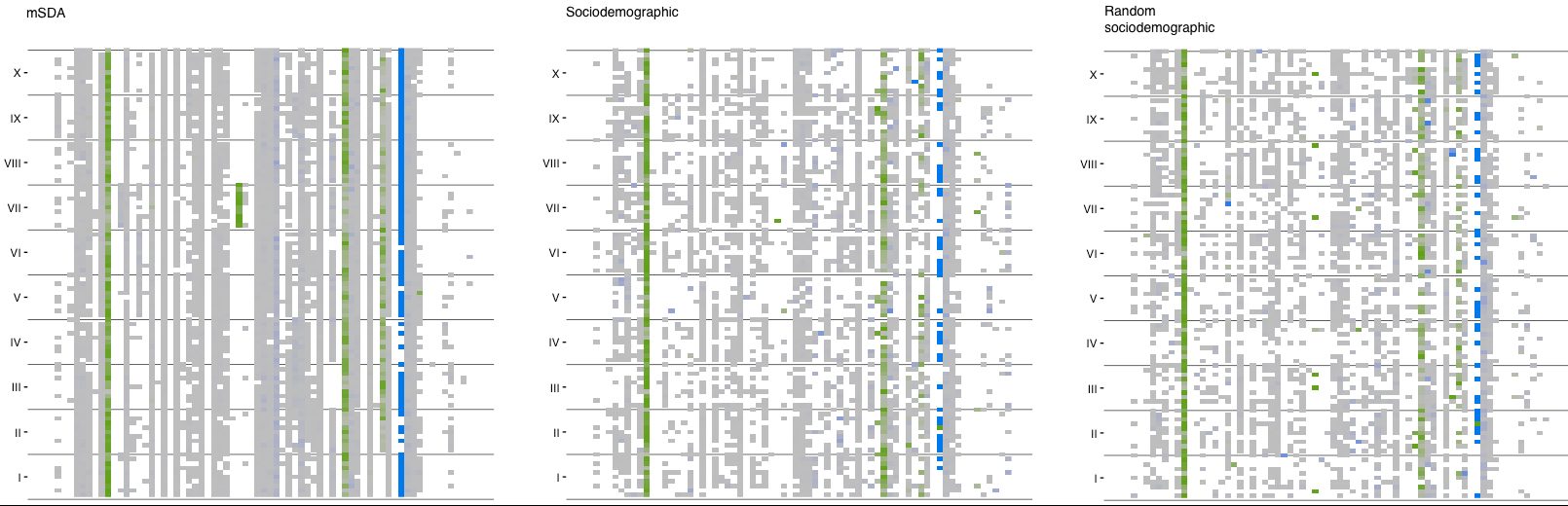
The development of this new methodology could help to accurately infer the interest of a customer on a certain financial product by analyzing their behavior in other expense categories to that of similar customers, much like situating each client in a georeferenced spatial environment related to their behavior. This could even allow to understand the profile of new customers and group them without having to rely solely on variables like zip code, income or age, that may be misleading.
Baldassini, who has co-authored a paper on the topic with Rodríguez, believes that his research can be translated to different use cases for clusterization and expenditure prediction.
The work of Client2vec relies on a well-known model, the marginalized denoising autoencoder, to transform transactional data into a simpler matrix that maintains the relational structure of different purchasing behavior, allowing to represent a client as a point in a multidimensional space. Then by applying nearest neighbor algorithms to these points, it is possible to find similarities among clients in a diverse range of target categories.
So far these techniques have been applied to test data of travel preferences but could be scaled with the purchase data of customers from POSs or other sources of more real-time data. One of the possible applications in the future is to tailor product recommendations to our clients in a more accurate way, just by looking for responses and preferences in groups of similar behavior. In this way, we could avoid inconveniencing the customer with offers or recommendations that are not relevant to their needs at a given moment.
Read Baldassini and Rodríguez’s research here.