
Clasificación de Texto Financiero: Métodos de Embedding de Palabras
La clasificación de texto adquiere gran relevancia en muchos de los retos de negocio que abordamos en BBVA Data & Analytics. En este sentido, la categorización de transacciones en cuentas es una de las soluciones más útiles y aplicables, y ha ido creciendo hasta convertirse en en una de las características más reconocibles de la premiada app móvil del BBVA. Asignar cada una de las operaciones realizadas por un cliente a una categoría de gasto es fundamental para la gestión de una cuenta, ya que permite, entre otras funcionalidades, navegar a través de categorías de importancia, como “gastos del hogar”, “seguros” o “viajes”. Además, esta categorización añade una etiqueta semántica que resulta esencial para el desarrollo de otros servicios -por ejemplo, para la previsión de gasto en cada categoría-. Lo que sigue es un resumen técnico de los aprendizajes adquiridos trabajando con embedding de palabras para las categorizaciones de pequeñas descripciones en transacciones financieras.
En el aprendizaje autónomo, el problema de la clasificación de texto es definido de la siguiente manera: dada una pareja de datos (sj , cj ), donde sj es una cadena de texto y cj es una de las posibles etiquetas o categorías para el texto dado, nos surge la necesidad de conocer la función de clasificación F atribuyendo etiquetas a una muestra arbitraria de cadenas de texto.
Introducción al embedding de palabras
Al abordar los problemas de clasificación de texto mencionados anteriormente, una de las cuestiones principales que surgen es cómo tratar los textos computacionalmente. En este sentido, los científicos de datos tratan el texto como un objeto matemático: aplicando diferentes técnicas, se han encontrado métodos para transformar las palabras en puntos de un espacio euclídeo con una dimensión conocida. Esta transformación asigna un vector único a cada palabra que aparece en el vocabulario, y es conocida como embedding.
Con esta transformación matemática somos capaces de realizar nuevas operaciones en texto que no eran posibles anteriormente: en un espacio con D dimensiones podemos añadir, restar y mapear múltiples vectores, entre muchas otras operaciones. Por consiguiente, con la intención de evaluar esta “transformación” (embedding), es deseable que estas “nuevas” operaciones puedan traducirse a propiedades semánticas entre las palabras existentes, propiedades que no estaban claras antes de la transformación. En concreto, en la mayoría de transformaciones el producto escalar de vectores normalizados (similitud coseno) es utilizado como una función de similitud entre palabras. Implícitamente, la mayoría de transformaciones de texto significantes dependen de hipótesis distribucionales, que estipulan que palabras que aparecen en el mismo contexto tienen un significado similar.((Se puede llegar a conclusiones únicamente cuando se tiene suficiente texto. De hecho, aparecen defectos en los métodos que asumen estas hipótesis cuando no existe suficiente texto disponible.))
Otro problema relevante que no se aborda en este artículo es cómo combinar vectores de texto para crear representaciones vectoriales de oraciones, enfoque que formó parte de mi investigación en 2018. En este artículo se aborda la simple aproximación de normalizar la media de vectores de texto, ya que se trata de la construcción matemática más natural, aunque no siempre es el mejor método de representación.
Context-count y context-prediction embeddings e “información privilegiada”2
Existen muchas maneras de realizar el embedding de una palabra. Una posible distinción de las diferentes técnicas de embedding se establece entre los embeddings context-count based y context-prediction based, dependiendo de si los vectores son obtenidos a través del recuento de apariciones de palabras o mediante la predicción de palabras en un contexto dado. Los modelos tradicionales dependen mayoritariamente de matrices obtenidas mediante el recuento de apariciones de palabras y los contextos en los que aparecen, mientras que el último intento de predecir una palabra basada en su contexto (o viceversa) es mayoritariamente utilizado por modelos neuronales. Es importante tener en cuenta que estos tipos de embeddings tratan de extraer información de una palabra utilizando su contexto, y por tanto dependen, implícitamente, de hipótesis distribucionales. Una buena explicación sobre la factorización de matrices en métodos de conteo puede encontrarse aquí.
Adicionalmente, respecto al objetivo de la clasificación de texto, existe otra posible diferencia entre los métodos de embedding. Una vez que la base de datos está etiquetada, se podrían utilizar las etiquetas de oraciones para crear embeddings con mayor significado. En algunas ocasiones la comunidad se refiere a estos métodos en el sentido de tener acceso a información privilegiada, una idea que también es utilizada en visión artificial para ordenar imágenes.
Algunos ejemplos de embedding de palabras
Bag of Words
El embedding más común es conocido como Bag of Words (BoW), y consiste en mapear cada palabra de un vocabulario V {wj}j∈N como un vector codificado en caliente. En otras palabras, un vector formado por ceros, excepto un único 1 situado en el lugar correspondiente respecto a la posición que representa esa palabra en el índice.
Hay importantes inconvenientes que siguen a esta definición, aunque este embedding simple es muy eficiente desde el punto de vista del rendimiento, como veremos más tarde en este artículo. Algunas contrapartidas de BoW son la incapacidad de elegir la dimensión del embedding, que es fijada por el tamaño del vocabulario, así como la dispersión y dimensión del embedding resultante, teniendo en cuenta que el tamaño del vocabulario puede ser extremadamente grande. Sin embargo, el factor diferencial más importante de BoW respecto a cualquier otro embedding es que el modelo únicamente aprende del vocabulario y no del texto de la base de datos, haciendo imposible adquirir ninguna noción de similitud o distinguir si dos palabras son diferentes o no (con este codificado, todas las palabras son equidistantes).
Metric Learning
Una posible mejora de BoW en un embedding que ajuste los vectores aprendiendo una métrica que sea capaz de diferenciar oraciones en nuestra base de datos considerando las etiquetas, y, de este modo, tener acceso a major información de las similitudes entre palabras parecidas.
En resumen, el Metric Learning surge de un “data-free embedding” (como BoW) y propone un embedding transformado. Esta transformación es realizada de manera que los embeddings de las oraciones de la misma clase aparecen juntas, mientras que se encuentran alejadas de los embeddings de las otras clases. Esto da lugar a un embedding que tiene en cuenta la información semántica proporcionada por las etiquetas de las oraciones.
Word2Vec
Por otro lado, el embedding no supervisado más ampliamente utilizado es Word2Vec, desarrollado por Tomas Mikolov. Word2Vec aprende embeddings de palabras mediante pruebas de predicción en un contexto dado (Continuous Bag of Words) o intentando predecir un contexto dada una palabra (Skip-Gram), siendo, en consecuencia, un embedding context-prediction dependiente de hipótesis distribucionales. Word2Vec ha logrado muy buenos resultados en tareas relacionadas con texto. Con suficiente texto, la similitud coseno detecta con precisión los sinónimos del texto, así como los embeddings con la información suficiente para resolver preguntas tales como “Hombre es a Mujer, lo que hermano es a…”. Con aritmética vectorial podemos determinar que el resultado es el vector que representa a “Hermana”. Ésto es utilizado con mucha astucia para reducir el sesgo de los embeddings. El ejemplo anterior es, además, ilustrativo de cómo los embeddings puede aprovechar la estructura de un espacio euclídeo para obtener más información de palabras que no se pueden detectar en un espacio original de las palabras.
Práctica con embedding de palabras
En esta sección presentaré algunos resultados sobre el uso de embedding de palabras que aprendí durante mi tiempo en BBVA Data & Analytics:
- Heurísticas para conocer cuándo Word2Vec ha aprendido una solución aceptable
- En bases de datos pequeñas, podemos utilizar metric learning con pequeñas cantidades de oraciones supervisadas y hacer trabajar embeddings con la misma calidad con la que Word2Vec entrena millones de oraciones
Impresiones entrenando Word2Vec
Estas percepciones se centran principalmente en la elección de la cantidad correcta de epocs durante el entrenamiento de un modelo Word2Vec, que buscan definir una métrica e hipótesis sobre el comportamiento en el aprendizaje de sinónimos de Word2Vec cuando no hay suficientes datos disponibles.
La cantidad de epocs que un modelo de Word2Vec tiene que entrenar es un hiper parámetro que puede dificultar el ajuste en algunos casos. Sin embargo, utilizando la evolución de la matriz de similitud MtM, donde M es la matriz normalizada, nos puede servir para conocer si nuestro word2vec ha aprendido la representación vectorial adecuada o no. Por medio de la fórmula de recall (MtM)ij = similarity(wi, wj ) and −1 < (MtM)ij < 1lo deseable es que solo los valores que son sinónimos tengan valores altos. Como se puede apreciar en la figura 1, el cuadrado de la suma de los elementos no diagonales de MtMse incrementa y posteriormente se estabiliza. Hay que destacar que un valor más bajo de esta métrica no significa un mejor entrenamiento.
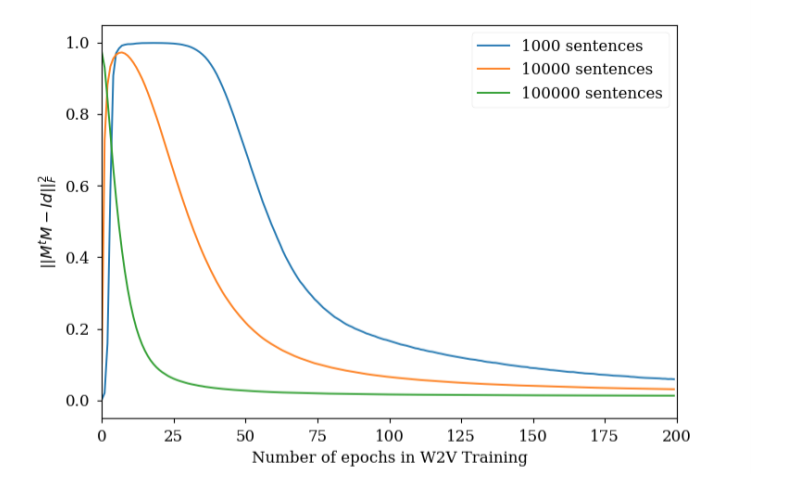
Este comportamiento puede ser interpretado de la siguiente manera: en primer lugar, el modelo inicia de forma aleatoria los vectores asignados a cada palabra, para luego mover la mayoría de ellos a la misma región del espacio del embedding. Posteriormente, como el modelo encuentra diferentes palabras en diferentes contextos, las separa hasta situar cerca únicamente a los sinónimos. Algo más de análisis sería necesario para confirmar esta hipótesis sobre cómo la distribución de los vectores afecta al entrenamiento.
Como hemos mencionado anteriormente, Word2Vec proporciona sinónimos con alta precisión, diferenciando incluso entre representaciones de la misma palabra, como por ejemplo “third” o “3rd”, utilizando la similitud coseno de vectores normalizados. Esto es así porque, cuando el modelo ha explorado suficiente texto, aprende a identificar que los contextos de “third” y “3rd” con muy similares en la mayor parte de las ocasiones. Sin embargo, cuando no hay suficientes datos (o el modelo no es entrenado con suficientes epocs), en ocasiones los sinónimos encontrados (aquellas parejas de vectores con similitud coseno) muestran un comportamiento no encontrado en embeddings totalmente entrenados: las palabras que el modelo ha encontrado siempre juntas son tratadas como sinónimos. Por ejemplo, si una cantidad pequeña de texto suele contener “BBVA Data” pero no contiene ningún ejemplo de “BBVA” sin “Data” a continuación (o viceversa), el modelo no separará los vectores entre estas dos palabras porque siempre aparecen en el mismo contexto. Así, el modelo asignará una alta similitud. Esto puede ser útil para advertir de la necesidad de incluir más texto o más entrenamiento. En conclusión, pensar en el word2vec como una técnica que separa todos los vectores y solo mantiene la cercanía de las palabras similares en lugar de un unificador de palabras similares puede ser útil a la hora de determinar si nuestro embedding está entrenado correctamente.
En la siguiente figura animada se muestra la evolución de la matriz MtMen entrenamiento, algo que puede ayudar desarrollar cierta intuición sobre el proceso de entrenamiento. En la animación, los índices bajos corresponden a las palabras más frecuentes, y se observa cómo el modelo es capaz de diferenciarlas con pocos epocs.
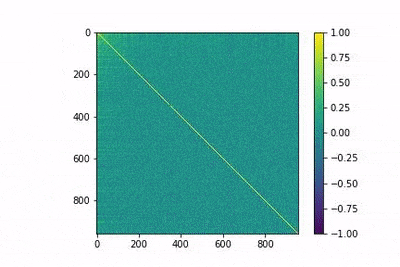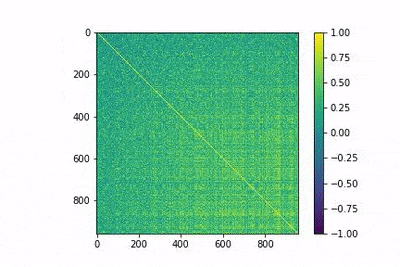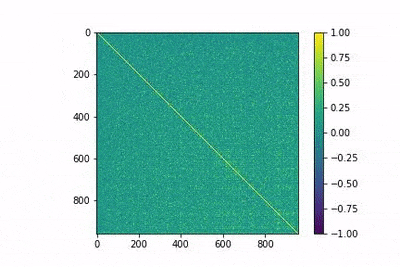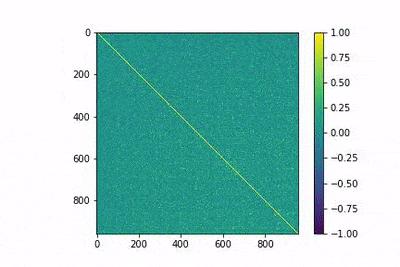
Embeddings de palabras supervisados frente a no supervisados en pequeños conjuntos de datos
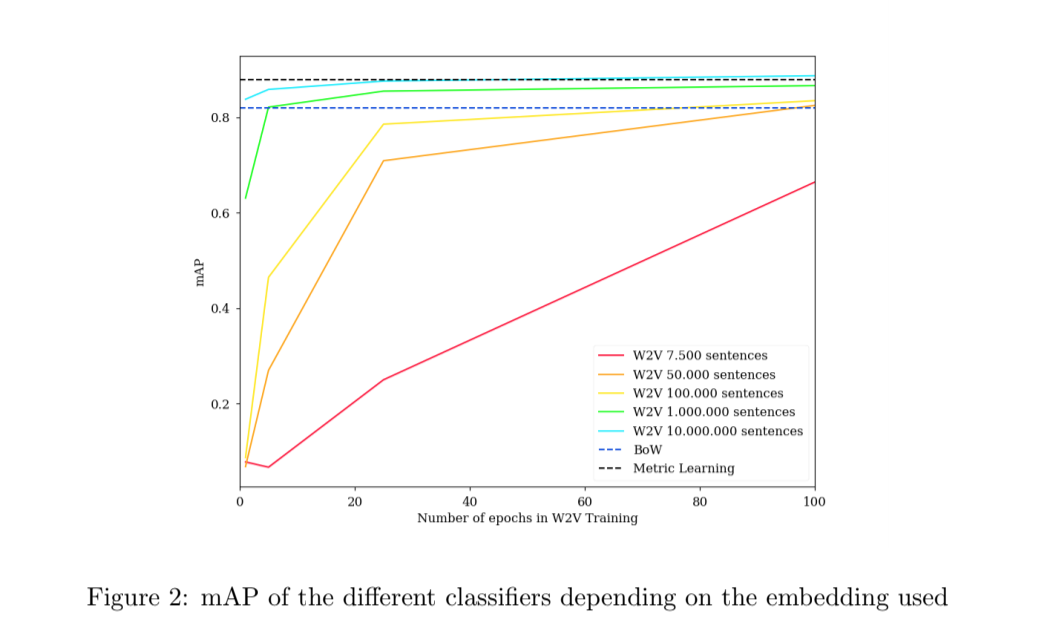
Complementariamente, se llevó a cabo un experimento para evaluar los embeddings de palabras en una pequeña base de datos de preguntas cortas. En concreto, 20.000 preguntas de Stack Overflow, etiquetadas entre 20 posibles categorías. Los embeddings de BoW and Metric Learning fueron entrenados utilizando las oraciones de la base de datos y se realizó el etiquetado con un clasificado de regresión logística. Además, utilizando preguntas no etiquetadas de Stack Overflow, diferentes Word2Vecs fueron entrenados con diferentes cantidades de oraciones, incluyendo frases del propio conjunto de datos. La media de precisión principal es utilizada como la métrica para comparar entre los clasificadores. Los resultados se pueden comprobar en la figura 2. Como se puede observar, Word2Vec necesita una gran cantidad de oraciones para superar a Metric Learning (incluso entrenando Word2Vec con 2,5 veces más de oraciones de la base de datos original, no se supera por mucho BoW). En conclusión, BoW y especialmente, Metric Learning, son mucho más adecuados en el caso de no disponer de mucho texto. Está bastante claro que los embeddings de palabras basadas en la predicción son superiores a cualquier otro embedding, pero, en este caso particular, (un pequeño conjunto de datos de oraciones cortas) un enfoque más clásico arrojó mejores resultados.
Conclusiones y reconocimientos
Para algunas aplicaciones, no es sencillo adquirir una gran cantidad de texto y, por esta razón, el modelo Metric Learning u otros similares ejecutan bien utilizando únicamente la pequeña cantidad de datos del propio conjunto de datos.
En resumen, mis prácticas de verano en BBVA Data & Analytics resultaron en una muy buena experiencia de aprendizaje y me ayudaron a explorar las profundidades del Procesamiento de Lenguaje Natural (NLP), gracias a la orientación de mis mentores. Especialmente, me gustaría agradecer a José Antonio Rodríguez su paciencia y su tiempo supervisando tanto mis prácticas en la empresa como todos los nuevos conceptos que me ha enseñado.