Acelerar el flujo de trabajo en Ciencia de Datos
Existen muchas respuestas posibles a la pregunta “¿qué hace un científico de datos?”. Una que nos gusta especialmente es que un científico de datos es quien se encarga de trabajar con los datos para ayudar en la reducción de ineficiencias en productos, servicios o procesos. Así, vemos empresas de venta al por menor incorporando científicos de datos para mejorar la eficiencia en los envíos, mientras la banca los utiliza, por ejemplo, para predecir la siguiente transacción más probable con el objetivo de ahorrar tiempo al cliente.
Pero el trabajo que realiza un equipo de científicos de datos tampoco está libre de ineficiencias. En muchas ocasiones, como científico de datos te has encontrado con afirmaciones como “los aspectos relacionados con ingeniería representan el 90% del trabajo”. Es por esto que algunas herramientas permiten la automatización de tareas de ingeniería. O quizás has escuchado: “el refinamiento de los datos es la tarea más tediosa”. Y por esta razón algunas compañías también han desarrollado herramientas para navegar los datos de forma más eficiente. Desde una perspectiva externa, podríamos definir estas herramientas como “ciencia de datos para científicos de datos”.
Un claro ejemplo de “asistencia completa” para científicos de datos (y en general, otros usuarios del aprendizaje autónomo), es Google’s AutoML, una serie de servicios de aprendizaje autónomo de fácil uso construidos entorno al concepto de búsqueda de arquitectura de redes neuronales y de transferencia de aprendizajes. En uno de estos servicios, AutoML ofrece a los usuarios la posibilidad de subir bases de datos de imágenes y empezar a construir modelos con sólo unos clicks. Este en un ejemplo de la “mercantilización” de las herramientas de aprendizaje autónomo: permite a los no expertos acceder a los beneficios de esta tecnología.
Sin embargo, esta rápida “mercantilización” también plantea algunos desafíos y, de hecho, algunas personas creen que estos productos están “destruyendo puestos de trabajo en ciencia de datos”. ¿Es justo decir que el trabajo del científico de datos puede ser automatizado? En nuestra opinión, sería más adecuado plantearnos qué tareas que suelen caer bajo la responsabilidad de los científicos de datos podrían ser automatizadas, o, más bien, facilitadas.
¿Qué hace un científico de datos?
Los esfuerzos para documentar “el proceso de la ciencia de datos” son casi tan viejos como la propia existencia de la ciencia de datos. De hecho, muchos de esos procesos han heredado de características de Crisp-DM, una metodología originalmente diseñada para la minería de datos que define una tarea de ciencia de datos como un proceso con los siguientes pasos generales:
- Conocimiento del negocio
- Comprensión del dato
- Preparación del dato
- Modelado
- Evaluación
- Despliegue en producción
Éstas han sido las bases a la hora de proponer muchos modelos de “procesos de ciencia de datos” en la industria1 . Otro ejemplo, esta vez poniendo el foco en la experiencia de usuario y la importancia de la creación de prototipos, se pueden ver en este post de Fabien Girardin.
En BBVA D&A, nuestros compañeros César de Pablo y Juan Carlos Plaza hicieron un esfuerzo en documentar un flujo de trabajo integral de las tareas de ciencia de datos en los proyectos, que se puede consultar en el siguiente gráfico:
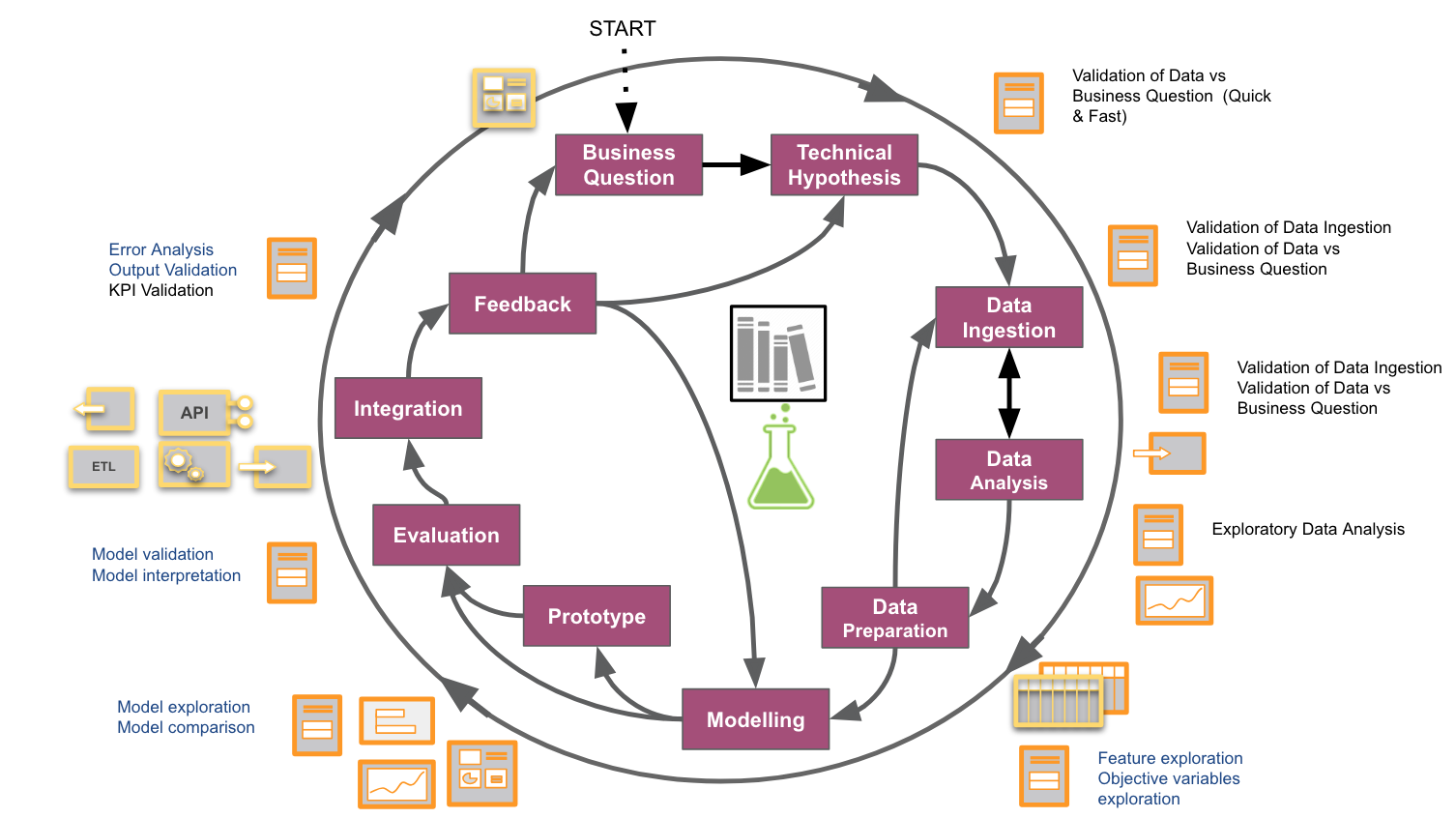
Con nuestros proyectos aumentando en número y diversidad, sentimos la necesidad de abstraer y documentar un flujo de trabajo, no sólo para nuestra propia comprensión y mejora, sino también para hacernos una idea de cómo encajarlos mejor en prácticas corporativas como los procesos ágiles, o para difundir una cultura basada en datos. Construimos este proceso observando desde nuestra propia perspectiva el trabajo desarrollado en propuestas anteriores e ilustrando cada paso con las subtareas específicas involucradas. Si bien esta cifra puede ser específica para nuestros proyectos, aquellos familiarizados con la ciencia de datos probablemente reconocerán muchos pasos comunes.
Algoritmos para asistir o automatizar tareas de ciencia de datos
Como punto de partida, creemos que reemplazar los científicos de datos por algoritmos de ciencia de datos, a pesar de algunas afirmaciones, está más cerca de la ciencia ficción que de la realidad. Si bien profundizar en los porqués de esta creencia probablemente daría para la publicación de otro artículo, mencionaremos dos factores principales aquí:
- Los flujos de trabajo en ciencia de datos contienen comúnmente “incógnitas desconocidas”. Un ejemplo es que, tal y como se debatía en el libro Agile Data Science 2.0, es difícil decir si un proyecto es viable hasta que no se ha concluido el trabajo con los datos – desde la cantidad / formato / calidad / contenido de los datos que determinarán si una aplicación es viable o no. Esta es la principal diferencia respecto a los proyectos de software tradicionales. O, en muchas ocasiones, no podemos saber si un producto de datos es útil para el cliente hasta que no es puesto en sus manos (ver diagrama). En todo caso, la ciencia de datos es un proceso iterativo donde cada paso se construye sobre los aprendizajes de los pasos previos.
- El trabajo de un científico de datos implica un gran conocimiento del dominio: elegir la pregunta adecuada, las fuentes de datos, métricas, restricciones, incluso antes de configurar un “pipeline” que puede ser automatizado. De hecho, una contribución clave de un científico de datos es tender ese puente entre las herramientas técnicas (construidas o compradas) con el conocimiento (humano) del dominio.
Sin embargo, una vez adquieres la suficiente experiencia en un dominio, es posible identificar patrones de problemas que se repiten o puntos en común entre “pipelines”, para construir soluciones que nos permitan ahorrar tiempo en el futuro. La industria y la comunidad de código abierto ha sido imprescindible en soluciones para reducir las ineficiencias en los flujos de trabajo de la ciencia de datos. A continuación, presentamos una lista de ejemplos:
- Herramientas para ayudar en búsqueda de datos (Data Discovery)
- Amundsen: Motor de búsqueda de datos y metadatos para facilitar la búsqueda en bases de datos corporativas.
- Herramientas para la exploración de datos:
- Tensorflow Data Validation: Explora bases de datos rápidamente utilizando el marco de trabajo de Tensorflow.
- InspectDF: Una herramienta de R para resumir, inspeccionar y visualizar información dentro de un dataframe.
- Feature:
- FeatureTOOLS: Descubrir atributos desde datos tabulados.
- Ludwig: Herramientas para reutilizar representaciones (embeddings y capas de arquitectura) en Deep Learning para tipos complejos, como imágenes o textos.
- BBVA Data & Analytics también ha experimentado con embeddings con entidades de domínios específicos con client2vec.
- Hiperparámetros:
- Gpyopt: Optimización bayesiana para la exploración de hiperparámetros.
- Búsqueda de arquitectura de redes neuronales
- Definición y optimización de un pipeline de aprendizaje autónomo
- TPOT: Una librería de python descrita como “tu asistente de ciencia de datos” permite definir pipelines de aprendizaje autónomo y realizar optimizaciones automáticas de extremo a extremo.
- TransmogrifAI: Una librería de Spark/Scala para preparar y optimizar pipelines de aprendizaje autónomo.
- ML validación y evaluación de modelos
- What if: Una interfaz que permite explorar fácilmente e interpretar modelos entrenados, entender la influencia de features y ejemplos de resultados.
- SHAP: explicación de predicción de modelos de cajas negras.
- Uber Manifold : Herramienta para comparar modelos y depurarlos, así como para validar resultados de modelos con diferentes subconjuntos de datos.
- Despliegue de modelos:
- Amazon Sagemaker : un marco para la creación, entrenamiento y despliegue de modelos de aprendizaje automático que se enfoca en el despliegue en casos de uso común.
Hay muchos otros ejemplos. Hasta la fecha, hay unos 32 repositorios en Github con la etiqueta “automated-machine-learning”.
Nuestra aportación: embeddings de usuarios.
Esta sección describe brevemente un caso de uso experimental llevado a cabo en BBVA D&A donde intentamos desarrollar una “plantilla genérica” para resolver un tipo específico de problema recurrente. No nos atrevemos a llamarlo “patrón de diseño para ciencia de datos” para evitar el uso indebido de la jerga de ingeniería, ya que el término “patrón de diseño” tiene connotaciones técnicas específicas.
En nuestro caso, encontramos que algunas aplicaciones de BBVA relacionadas con la experiencia de usuario, como “compárate” o los sistemas de recomendación, creaban una representación del usuario basada en sus datos, normalmente llamada “incrustación”, y luego aplicaban algún algoritmo de clasificación o regresión sobre esta incrustación. Observamos que estas incrustaciones se construyeron desde cero para cada nueva aplicación.
Así que pensamos: si facilitas incrustaciones pre-computadas al científico de datos y una forma eficiente para recuperarlos, estás ofreciendo una herramienta para que los científicos de datos prueben fácilmente las incrustaciones disponibles antes de embarcarse en la construcción de incrustaciones más complicadas y adaptadas a la aplicación. La primera objeción siempre se traduce en la siguiente cuestión: ¿cómo puedo obtener incrustaciones independientes del dominio? Hay muchos ejemplos en la comunidad de aprendizaje autónomo donde se han obtenido incrustaciones genéricas de entidades que luego pueden reutilizarse (y optimizarse) contra tareas finales específicas. Probablemente, uno de los casos más conocidos es el de incrustaciones de palabras y word2vec.
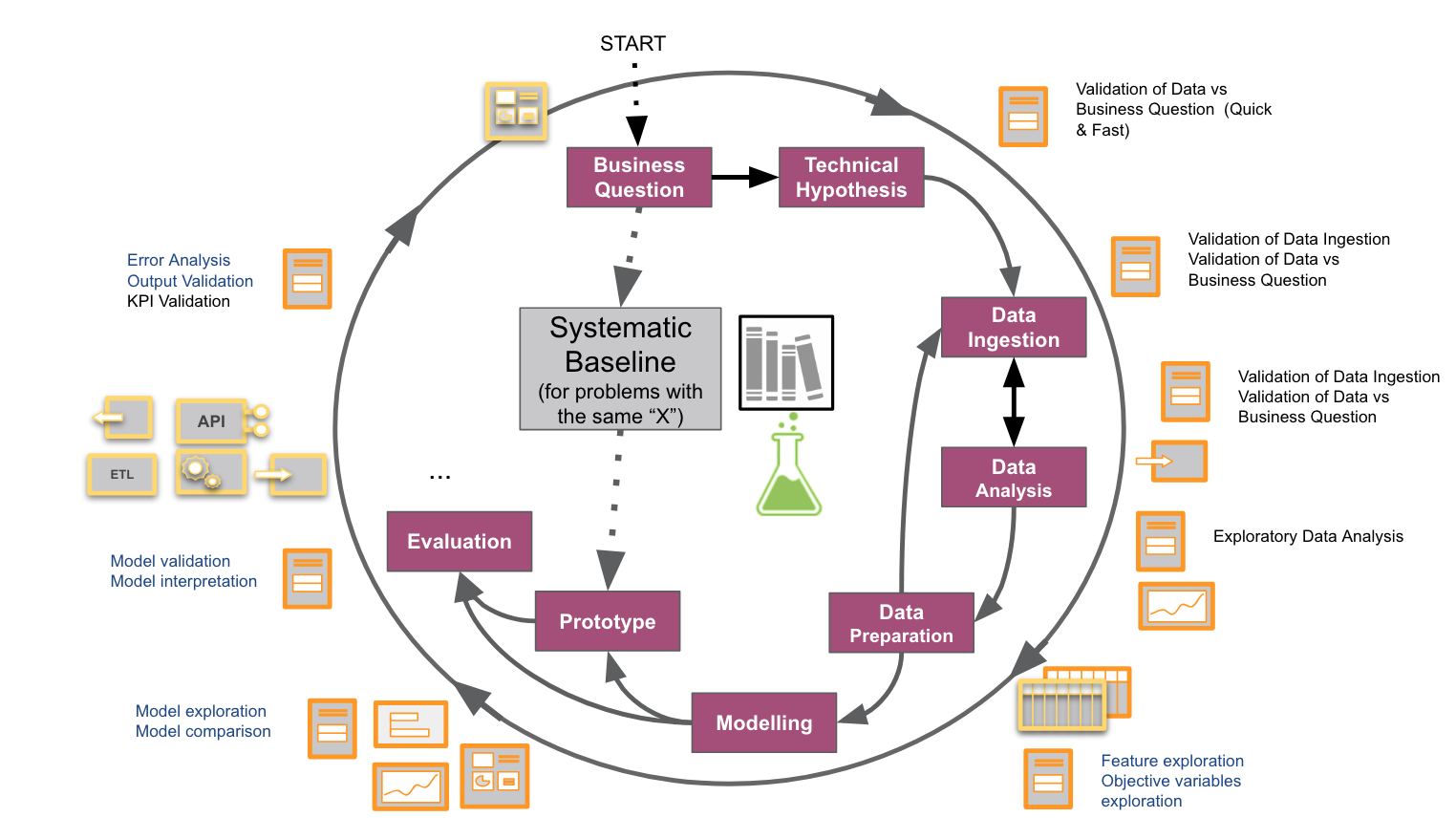
Como muestra el gráfico anterior, podemos ver este ejemplo como un atajo en el workflow anterior para poder pasar de la pregunta de negocio al prototipo de manera rápida. Por supuesto, este probablemente no será (y podría estar bastante lejos de ser), el modelo más óptimo. Pero tiene dos ventajas. Por un lado, ese “atajo” nos proporciona un ciclo de aprendizaje inicial muy barato. El aprendizaje es importante, especialmente en las primeras fases de un proyecto: cuando se valida una nueva idea. Por otro lado, ¿y si el desempeño utilizando incrustaciones pre-computadas era suficiente para tu idea?
Esto es lo que proponemos en nuestro paper experimental de client2vec, donde se explica la investigación interna llevada a cabo para obtener información sobre estos enfoques. Nos dimos cuenta de que las incrustaciones de mercantilización has sido llevadas a cabo por compañías como Twitter o Spotify.
En BBVA D&A estamos constantemente probando herramientas similares como la optimización bayesiana o nuestro propio pipeline de automatización para unos tipos específicos de modelos. ¿Sabes cómo aplicar este tipo de técnicas o conoces otros ejemplos?