
Predicciones con Incertidumbre en Modelos de Aprendizaje Profundo
En BBVA trabajamos desde hace tiempo para aprovechar los datos transaccionales de nuestros clientes y los modelos de Deep Learning para ofrecer una experiencia bancaria digital personalizada y relevante a nuestros clientes. Nuestra capacidad de prever los ingresos y gastos recurrentes en una cuenta es una de las más diferenciadoras de la industria. Este tipo de previsión ayuda a los clientes a planificar presupuestos, a actuar en un evento financiero o a evitar sobregiros, reforzando al mismo tiempo el concepto de “tranquilidad” que un banco como BBVA quiere transmitir.
La aplicación de técnicas de Machine Learning para predecir la recurrencia de un evento y la cantidad de dinero involucrada permitió el desarrollo de dicha funcionalidad. Como complemento a este proyecto, en BBVA Data & Analytics también invertimos en investigación para estudiar la viabilidad de métodos de Deep Learning en la previsión de cuentas1 , como ya explicamos en “There is no such thing as a certain prediction”. El objetivo no era tanto la mejora del sistema actual como la generación de conocimiento para validar el potencial de dichas técnicas.
Como resultado de dicha investigación, hemos observado que el uso de técnicas de Deep Learning permite reducir los errores de previsión. Sin embargo, también observamos que sigue habiendo muchas situaciones donde los gastos no son previsibles, y los modelos de Deep Learning para regresión no disponen de un mecanismo para determinar la incertidumbre de la predicción, es decir, su fiabilidad.
Por ello, no sólo es importante hacer buenas predicciones en términos generales, sino también detectar los casos en los que la predicción puede tener amplios límites y por tanto nos interesa modelar esa incertidumbre. Esto sería útil para mostrar a los clientes sólamente predicciones fiables, o para priorizar acciones relacionadas con la predicción. Para ello, hemos extendido la investigación a modelos de Deep Learning Bayesiano que modelan la incertidumbre a la vez que las predicciones.
Medir la incertidumbre para ayudar a los clientes
Pero, ¿qué es exactamente la incertidumbre? Aunque este concepto se encuentra a debate en los campos de la estadística y la economía, suele ser clasificado en dos categorías: la incertidumbre aleatoria – aquella que se refiere a la variabilidad de soluciones correctas dada la misma información- y la incertidumbre epistémica -la incertidumbre relacionada con nuestro desconocimiento sobre qué método utilizar para solucionar el problema o incluso nuestra ignorancia respecto nuevos tipos de datos que no vimos en el pasado-.
Desde un punto de vista matemático, lo que hacemos es buscar una función que, a partir de una información dada -el histórico de movimientos de un cliente-, nos devuelva el valor del siguiente movimiento que realizará. Sin embargo, este método tiene una limitación: en nuestro caso, dada la misma información -histórico de movimientos-, el resultado no tiene por qué ser el mismo -imaginemos dos clientes diferentes con el mismo histórico de gastos e ingresos pero con distinto comportamiento en el futuro-.
La siguiente figura muestra gráficamente el concepto de incertidumbre, y responde a la pregunta de cuál será el valor del punto rojo en el intervalo de tiempo dado. En la mayoría de situaciones reales, no es fácil decidir cuál será el siguiente valor de la línea roja (punto rojo).
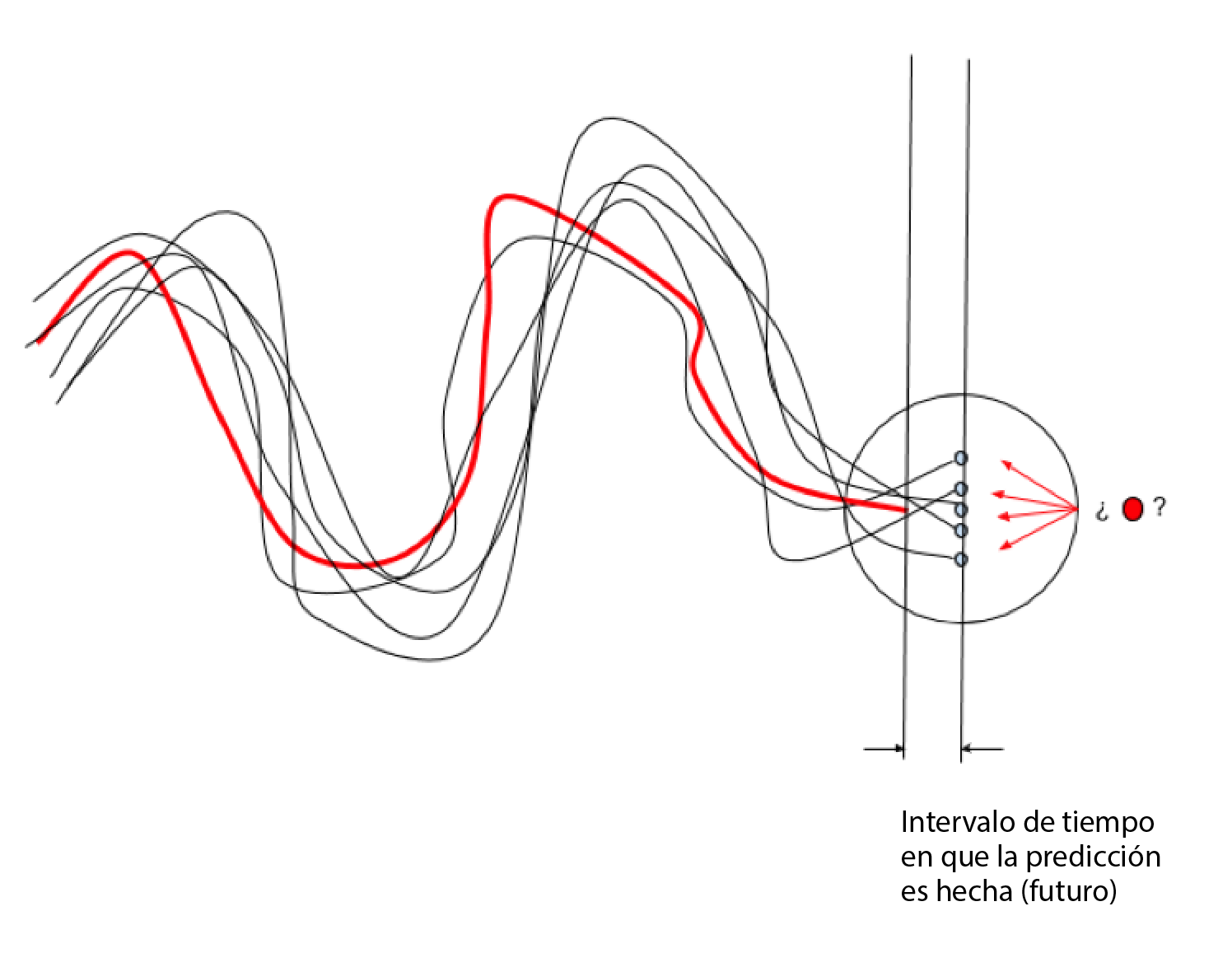
En este sentido, un modelo con y sin incertidumbre realizaría las siguientes predicciones:
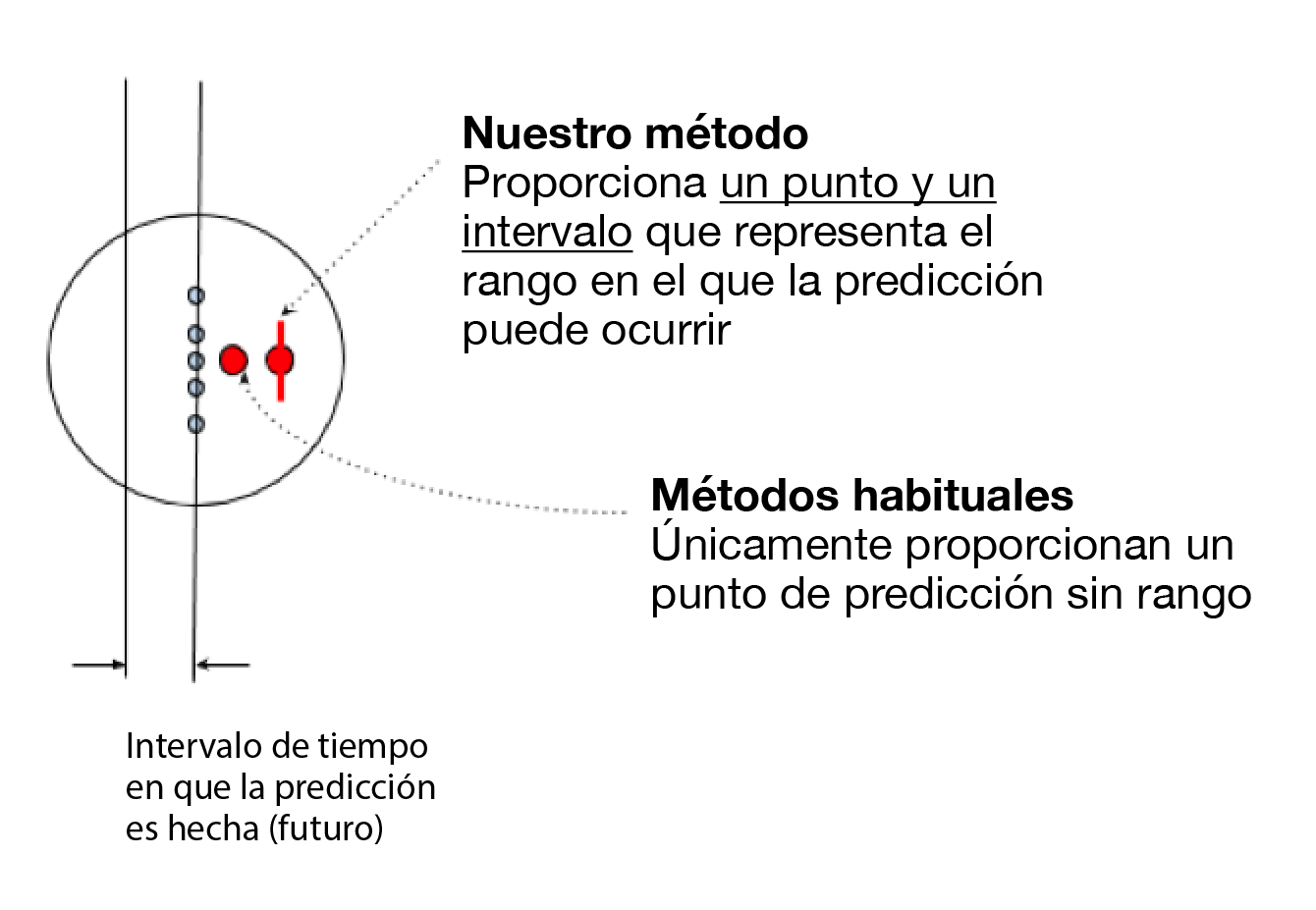
Uno de los modelos más avanzados para obtener resultados son los basados en Deep Learning (Aprendizaje Profundo), por su capacidad de aprender funciones muy versátiles de grandes conjuntos de datos. La forma común de construir estos modelos de Deep Learning proporciona una estimación puntual del valor a predecir, pero no refleja el nivel de confianza o seguridad en la predicción. Lo que nosotros buscamos es la probabilidad de que ocurran diferentes resultados a partir de la misma información histórica de diferentes clientes, esto es, la distribución de probabilidad.
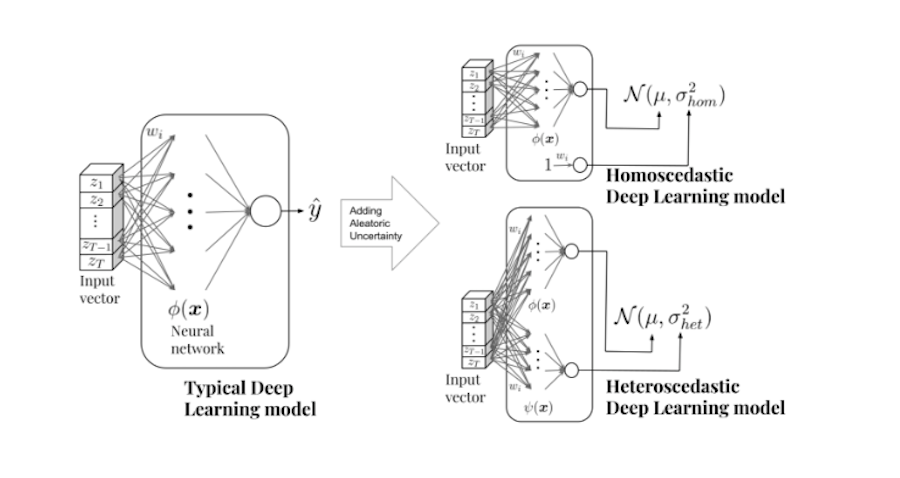
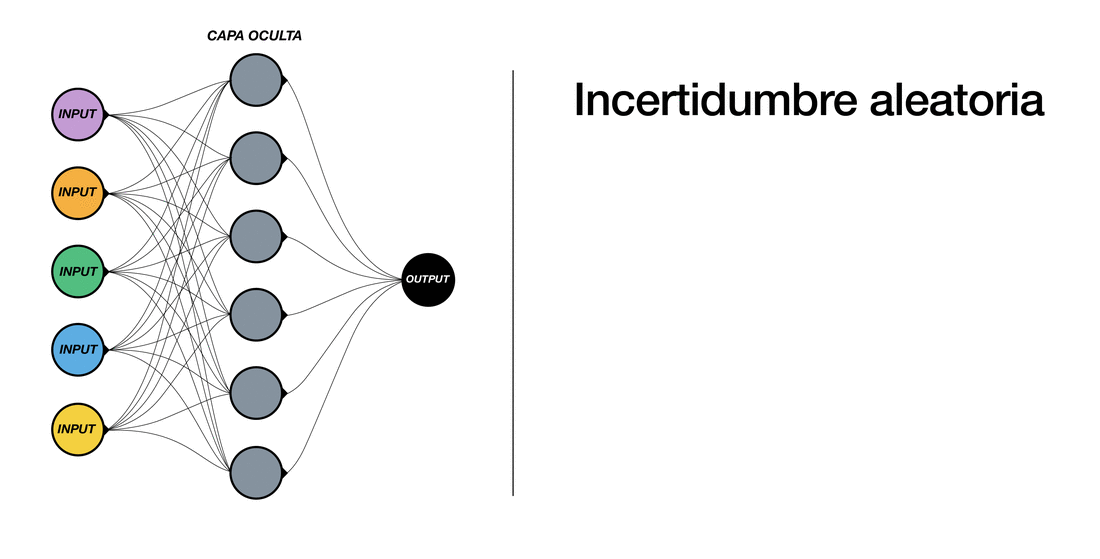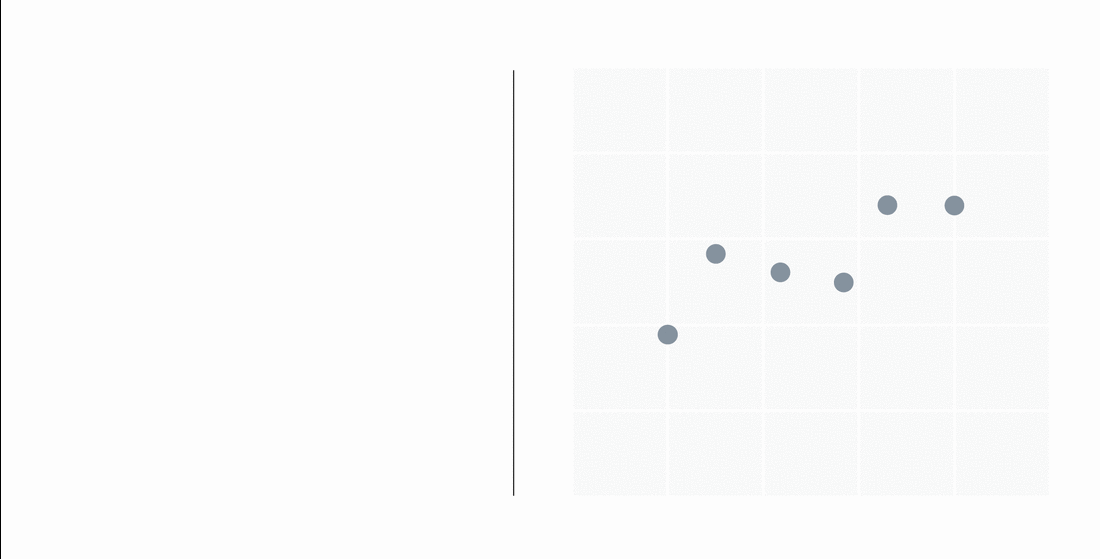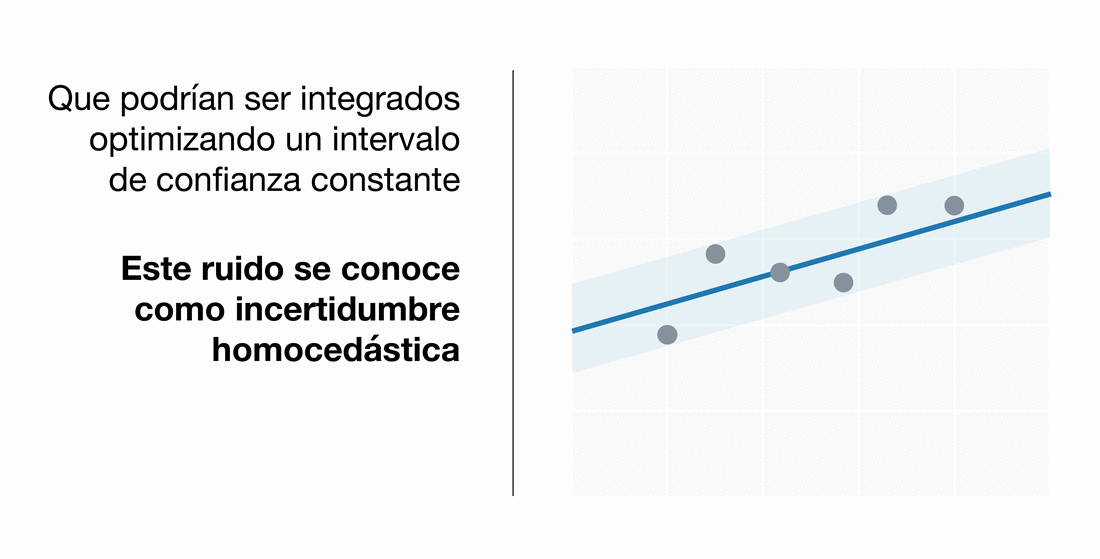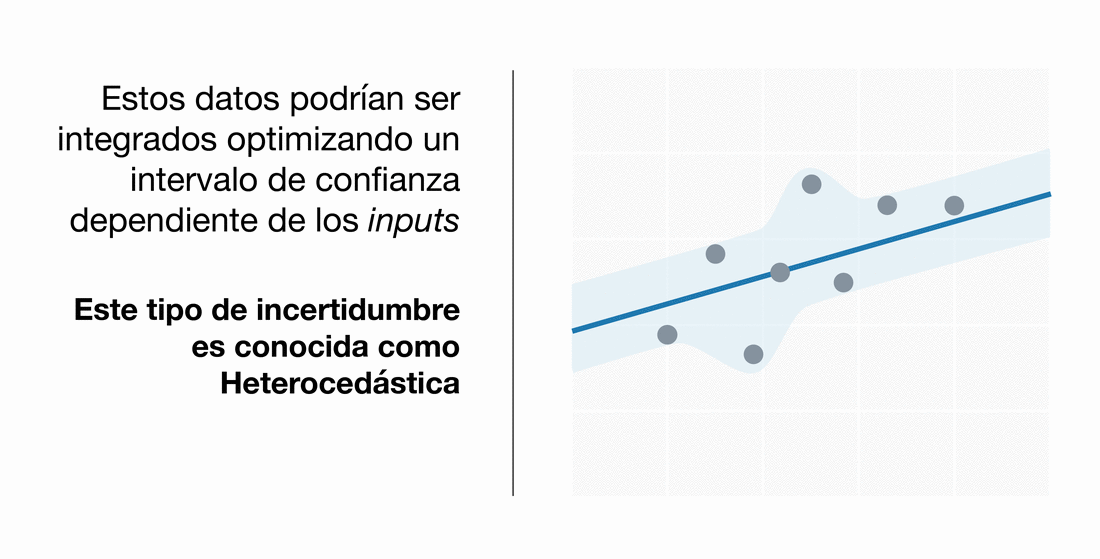
Podemos modelizar diferentes tipos de incertidumbre aleatoria. Por un lado, la incertidumbre homocedástica refleja una varianza constante para todos los clientes, mientras que nuestra implementación heterocedástica muestra la desviación respecto a la media para cada cliente, dado su patrón de gastos e ingresos.
Comparando este modelo con modelos epistémicos de Deep Learning, detectamos una clara mejora en el nivel de confianza de las predicciones respecto a las soluciones planteadas anteriormente, especialmente al poder medir la variabilidad.
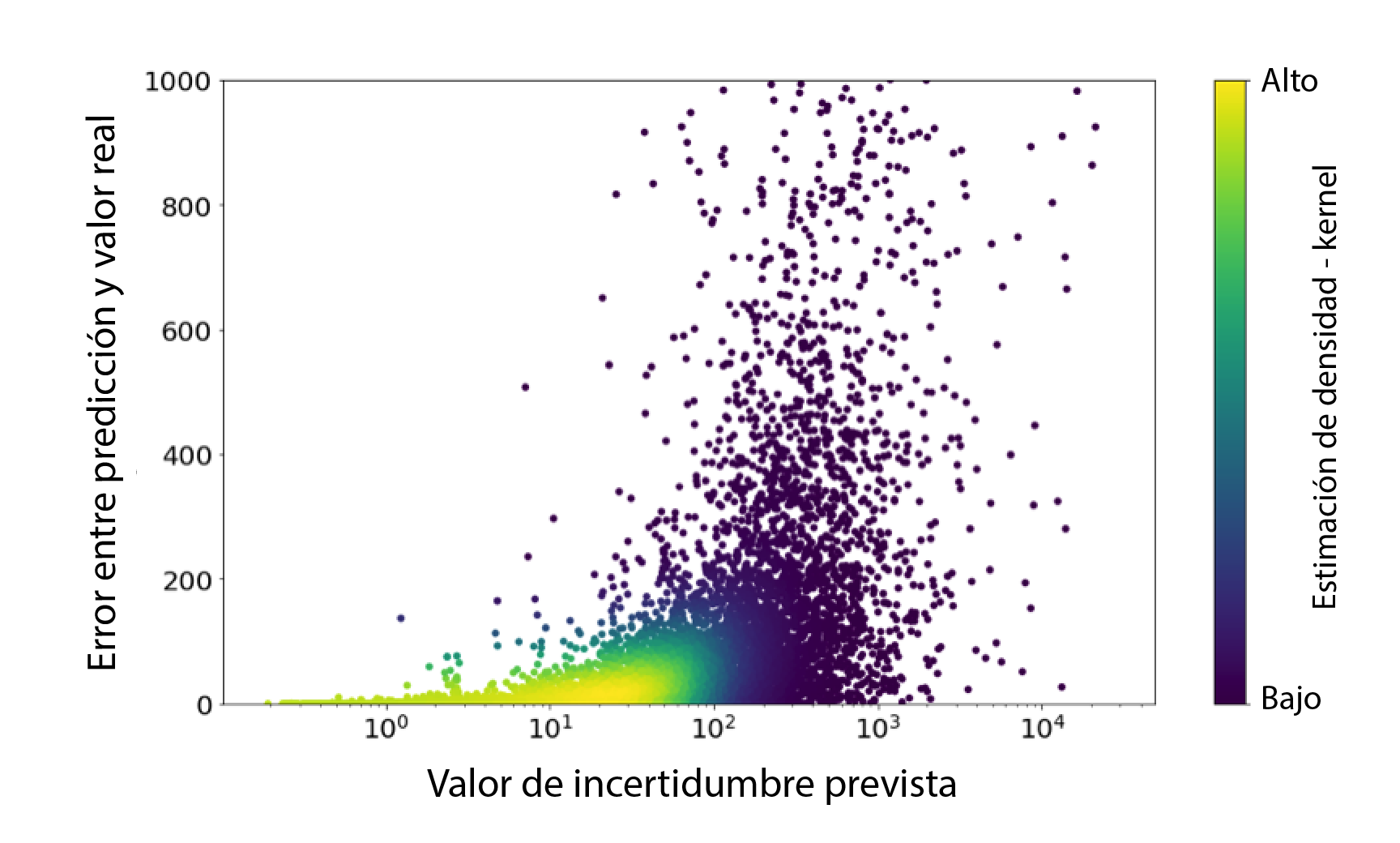
El tipo de incertidumbre que hemos tenido en cuenta adquiere gran relevancia a la hora de proponer un nuevo modelo que pueda predecir los próximos gastos e ingresos de los clientes. En el siguiente gráfico, cada punto representa un cliente situado según su error de predicción real y su puntuación de incertidumbre prevista. Podemos observar cómo los puntos amarillos (que representan a la mayor parte de los clientes) tienen un bajo error de predicción y una baja puntuación de incertidumbre, por lo que podemos entender esta puntuación como confiable.
Las posibles aplicaciones de este enfoque a soluciones de negocio van desde usos sencillos como la posibilidad de adelantarse a movimientos con gran precisión o recomendar medidas para mejorar la salud financiera, hasta más avanzados como notificar movimientos inusuales que aumentan la varianza de la predicción en un determinado momento de la vida del cliente. También se ha detectado un potencial enfoque desde el punto de vista del cliente, el cual, utilizando la incertidumbre, podrá valorar diferentes acciones financieras en base a sus propios criterios de riesgo.

Notas
- Esta investigación ha sido sintetizada en un artículo aceptado para publicación y presentado en el ECML-PKDD 2018, que está disponible en el servicio e-Print de arXiv. ↩︎
- Este artículo ha sido escrito por Axel Brando Guillaumes.