Eurovision 2018. Just Another Excuse to Demonstrate the Value of Data
⎋ Take a look at our data story
Data is getting more and more specific, with deeper dimension, greater levels of richness from which individuals or organizations can draw insights. Data is especially granular and structure when it affects the core operations of business, governments or other organizations. Surprisingly, this also stands true for events that have gathered the attention and passion of fans from all over the world: soccer, baseball, or the most important European music contest: Eurovision.
The Eurovision Song Contest started more than 60 years ago, bringing together audiences from the European Union and beyond its borders for an international marathon of televised music. A lot has been written about the politics of voting, the good neighbor influence, the changes in genre preference, or the media hype. At BBVA Data & Analytics we love data and (some of us) are Eurovision wonks. With a little help of Spotify, one of the companies that best applies advanced analytics and machine learning to music, and some basic statistical modeling we have analyzed the history of Eurovision winners and how this could help us establish some measure of propensity about whom could be at the top of this year contest in Lisbon, expected to attract over 180 million viewers, much more than a Superbowl.
Data is key
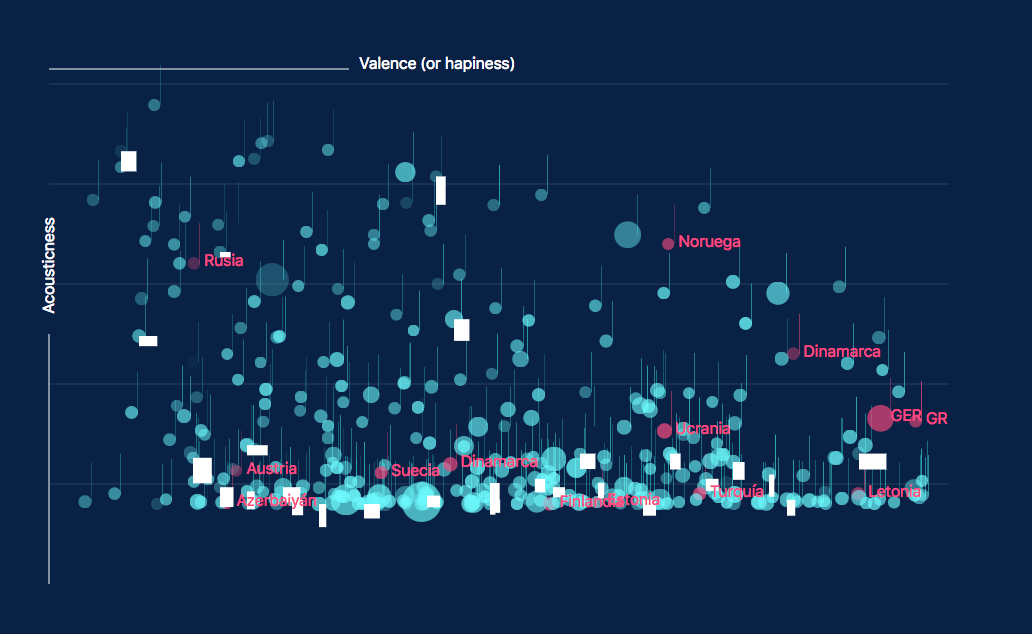
The same way BBVA tries to expand the data sensorization of their operations and customer experiences to improve product development and services, Spotify has deployed an extensive machine learning system to extract dozens of features from songs, artists, album, or playlist, that support a superb recommendation system. We have decided to rely on this data to develop an example of how data can help us understand events, trends, preferences, etc. We extracted for purely research purposes nine general features which provide some information on song style (loudness, danceability, valence, tempo, energy, liveness, key, acoustics and vocals) from all the available songs that have participated in Eurovision since 2000. We did not use the full dataset since 1956 in order to avoid distortions due to changes in genre preferences in previous decades (it seems reasonable to assume that the style and preferences of pop music change significantly over time, and there is recent research which seems to confirm so empirically; see here). We then label those songs to show whether they were on the top 5 contestants or not.
Visualization is the prism
By visualizing the data we’ve obtained we were able to identify trends, outliers, and determine the importance of some features over others. Valence, which describes how positive or sad a song is, has been tipping toward the pessimist side since 2000, with sadder songs reaching the top of the contest (yellow) since 2008, according to our linear regression model. This coincides with the beginning of the economic crisis, so it would be interesting to further investigate if there is a true cause-relation effect here.
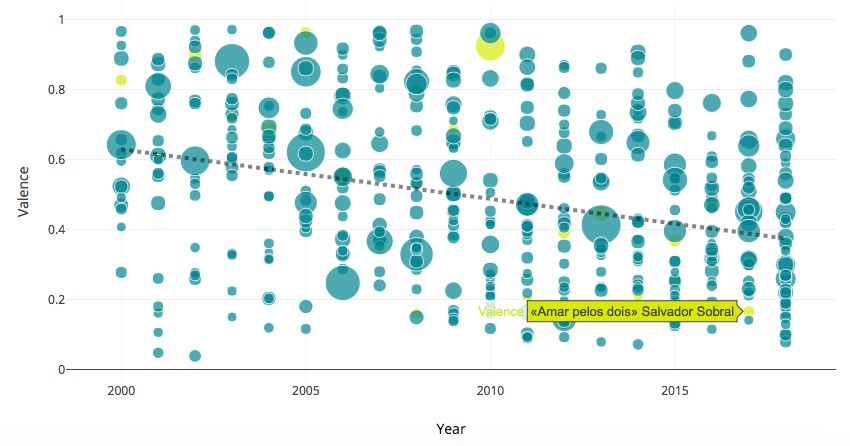
The typical Eurovision song is basically mellow, relatively acoustic, and increasingly less positive than the average song hit of the year in countries like Spain. The winners tend to be louder than the average (with the remarkable exception of Portugal -Salvador Sobral- last year), but not necessarily a song to hit the dance floor.
We have also extracted and analyze what makes a song a summer hit in Spain, and we have determined that the recipe that creates a great music hit in summer does not quite work with the audiences in Eurovision. This could mean that those loyal Eurovision viewers, and those who vote and participate, are not affected by considerations of danceability or happiness of the song but other variables: such as how romantic the song is, if they understand the message of the lyrics (English has become a common language in the contest) or if the nationality or eccentricity of the singer weighs in the final result.
Finding the hidden gems of this year’s Eurovision
Despite its limitations, we have used a Random Forest classifier, to understand which audio features make a song a potential Eurovision winner. This classifier algorithm solution applies a combination of several Decision Trees, a method that sift the most relevant features and lastly classify as a potential winner or not. The sifter weighs whether a song can be sent down the tree if it has a certain value of a set of features (i.e. tempo or danceability). Eventually, those that passed these binary tests will be the most similar to previous winners and therefore have a propensity to win with the “Eurovision’s formula”.
We highlight here the term “propensity” since we are aware that there can be factors for getting a high Eurovision score that are obviously not captured by the nine features. But we are not interested in a prediction, rather in getting insights from analyzing the propensity scores of song types.
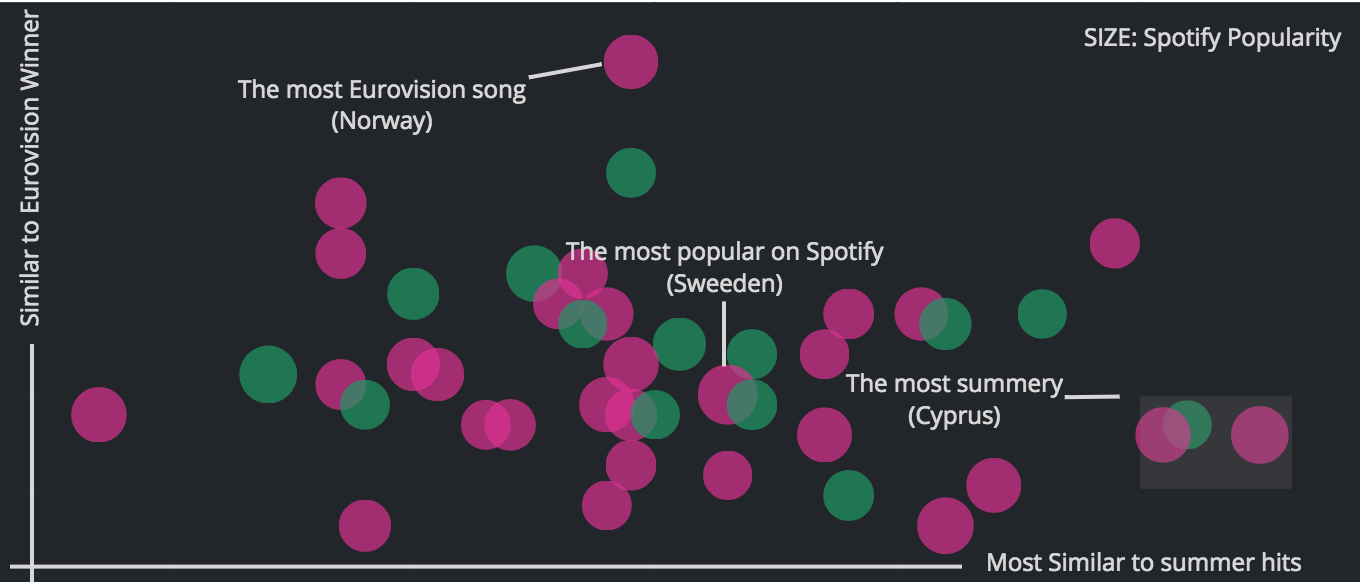
This year’s favorites, “Toy” (Israel) and “Fuego” (Cyprus), don’t seem to follow a typical Eurovision song, while “That’s How you Write a Song” (Norway) looks like the hidden gem which traditional Eurovision’s audiences would vote for. Hungary, Ireland, Spain, Austria, or Estonia are, according to our analysis, contestants that could surprise the viewers when the final votes are cast. Nonetheless, if, in fact, there is a correlation between economic growth and the taste for more happy songs, and if we analyse the propensity of the Eurovision contestants to become summer hits this year, Cyprus, Germany, Israel, and Sweden would be on the top of the list, coinciding with the top bet these years.
This Saturday we will know for sure whether a song that fits the pattern of a summer hit, could be aligned with what the majority of the very specific Eurovision audiences may like.